di Alessandro Rubini
Riprodotto con il permesso di Linux & C, Edizioni Vinco.
In tutti i sistemi informatici di una certa complessità le strutture dati rivestono un ruolo molto importante. La scelta delle strutture dati corrette influenza le prestazioni del sistema, l'occupazione di memoria, il comportamento in caso di sovraccarico, la risposta agli errori del programmatore come a quelli dell'hardware sottostante.
Tutti i programmatori sono abituati a gestire le proprie liste di strutture, inserendo e rimuovendo gli elementi secondo le semplici regole studiate a fondamenti di informatica. Molto più raramente però ci si spinge ad usare liste doppiamente collegate o alberi bilanciati, in quanto la corretta implementazione delle procedure necessita sempre di una certa quantità di tempo uomo, oltre a richiedere una buona conoscenza della teoria, in particolare per gli alberi bilanciati.
Perciò, se da un lato il codice per gestire una lista (come quello per gestire un vettore o uno stack) viene riscritto innumerervoli volte, ci sono situazioni in cui una struttura potenzialmente più efficente non viene utilizzata per privilegiare la semplicità di implementazione.
Un kernel, come Linux, è un applicativo notevolmente complesso che non si appoggia su librerie esterne. Per questo motivo nel corso degli anni vi sono state introdotte strutture dati complesse, con l'attenzione però a lasciare l'implementazione il più generica possibile. Questo per incentivare i programmatori a non replicare continuamente le stesse procedure, a non ripetere gli stessi errori in situazioni diverse, a non scartare soluzioni migliori per il timore della loro complessità implementativa.
In queste pagine analizzeremo a fondo l'implementazione delle liste e degli alberi bilanciati nella loro forma esportata dagli header del kernel, esaminando le idee che stanno alla base di tali implementazioni e valutando i loro effetti sulle prestazioni.
Storicamente, il programmatore ha sempre riunito nello stesso
contenitore il dato e il modo in cui è strutturato. Per esempio
dichiarando il campo next per gestire una lista
come nella struttura che segue:
struct int_item {
int value;
struct int_item *next;
};
In questa comune situazione, tutte le operazioni per la gestione
della lista ricevono come argomento un puntatore a struct
int_item e devono perciò essere riscritte quando la struttura
ospiti un dato diverso, pur trattandosi sempre di una lista.
La stessa considerazione vale
per organizzazioni più complesse dei dati, nel qual caso il campo
next viene sostituito da altri campi di controllo della
memorizzazione, come left
e right nel caso di un albero binario.
Considerando per ora solo il caso della lista, una prima
generalizzazione del concetto potrebbe
consistere nella separazione della lista in quanto tale dallo
specifico dato di interesse (nell'esempio precedente il valore
intero value). Tale generalizzazione si può realizzare
dichiarando una struct per la lista che includa
un puntatore generico (void *)
per riferirsi allo specifico dato di interesse, il cosiddetto
payload, carico utile:
struct generic_list {
struct generic_list *next;
void *payload;
};
I due programmi intlist e glist-int, parte degli
esempi relativi a questo articolo (datastruct-src.tar.gz),
sono programmi minimali ma completi che esemplificano l'uso dei approcci
appena descritti. Il loro compito è quello di di invertire una
sequenza di numeri interi ricevuti da stdin in formato ASCII.
Allo stesso modo, i programmi stringlist e glist-string
invertono una sequenza di righe di testo, purchè brevi. I programmi
glist- includono generic_list.h per sottolineare
come la struttura dati usata sia la stessa, cioè quella
appena riportata, formata da un campo next e un campo
payload.
I quattro programmi svolgono tutti lo stesso compito: invertono le righe del proprio input, inserendo ogni riga all'inizio di una lista e stampando l'intera lista quando si raggiunge fine file. Per semplicità, si assume che le righe siano più corte di 16 caratteri e rappresentino numeri interi in formato ASCII.
Per provare questo programmi e per misurare i relativi
vantaggi e svantaggi, useremo
una sequenza di numeri casuali presi da /dev/urandom.
Per esempio, una sequenza di 10 milioni di numeri interi può
essere generata e trattata come segue:
dd bs=4000 count=10000 if=/dev/urandom > /tmp/r40m od -t d4 -An -w4 /tmp/r40m > /tmp/nums time ./intlist < /tmp/nums > /tmp/n1 time ./glist-int < /tmp/nums > /tmp/n2 time ./stringlist < /tmp/nums > /tmp/n3 time ./glist-string < /tmp/nums > /tmp/n4
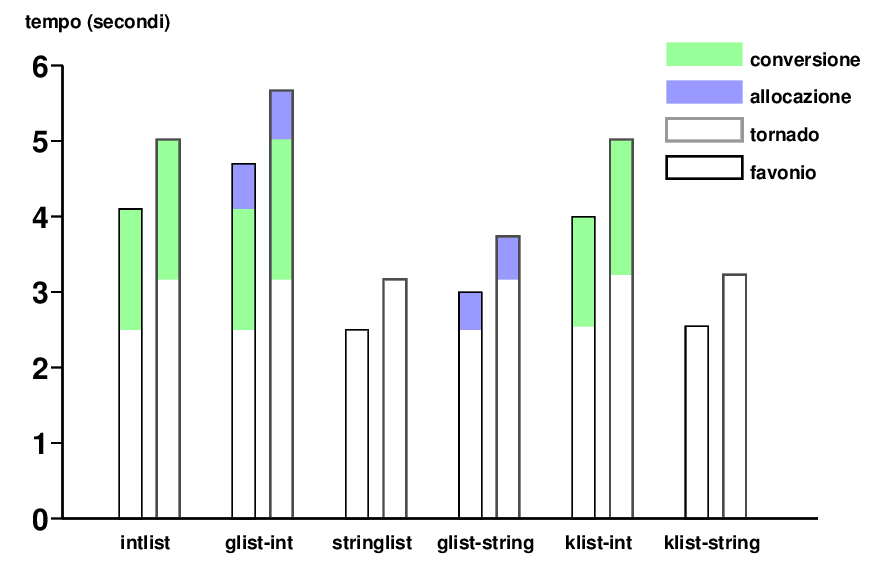
Le diverse caratteristiche dei 4 programmi risultano in tempi di elaborazione diversi, come discusso nel riquadro 1. Si nota in particolare come la lista generica, a fronte di una minor replicazione di codice, ha un costo computazionale non trascurabile rispetto alla struttura specializzata (ma non riutilizzabile).
Riquadro 1 - Prestazioni delle liste
I primi quattro programmi di esempio sono stati fatti girare su due macchine invocando i comandi indicati nel corpo dell'articolo, usando un tmpfs per non avere interferenze da parte di DMA e scambi di dati con il disco nei tempi misurati. Su favonio (Pentium Mobile, 3GHz) ho usato cinque milioni di numeri, su tornado (Core2, 2.33GHz) dieci milioni.
In figura 1 sono diagrammati i risultati in secondi, separando i tempi nelle loro componenti in base alle differenze tra i diversi programmi: i programmi che lavorano sugli interi impiegano più di quelli che lavorano sulle stringhe a causa della conversione dei dati, i programmi che usano la lista generica impiegano di più perché necessitano di due allocazioni (e liberazioni) per ogni cella della lista, invece di una sola.
La doppia chamata a malloc e l'indirezione necessaria per
accedere al dato hanno un costo non trascurabile (qui per esempio
supera il 10% del costo totale di tutto il programma), anche perché
il nuovo dato risulterà probabilmente in una linea di cache diversa
da quella che ospita il puntatore next.
Le ultime due coppie di misure sono relative alle liste del kernel, introdotte in seguito.
Nonostante le quattro implementazioni svolgano correttametne il proprio lavoro, va notato che una lista semplice non può servire ad altro che ad invertire il proprio input: non è possibile modificare i programmi per gestire un accodamento FIFO, per il quale servono liste bidirezionali (volgarmente dette "doppiamente linkate") oppure altre strutture meno pulite, come un puntatore all'ultima cella inserita.
Confrontata con quanto visto nei i quattro semplici esempi, l'implementazione delle liste utilizzata nel kernel mostra immediatamente le sue potenzialità. Si tratta di codice generico per gestire liste doppiamente linkate, raccolto in un file di header in modo da poter essere facilmente incluso e riutilizzato, mantenendo la genericità ma risolvendo il problema della doppia allocazione precedentemente discusso.
La novità principale alla base di <linux/list.h> sta
nel ribaltamento della struttura dati generica. Invece di includere il
payload all'interno della struttura lista
(direttamente o tramite puntatore)
si è scelto di includere la struttura di controllo all'interno del
payload, secondo questo schema:
struct payload_data {
/* ... */
struct list_head list;
/* ... */
};
struct list_head head;
L'idea sta nello svolgere tutte le operazioni relative alla lista
(inserimento, rimozione, scansione) usando la sola struttura
list_head,
dimenticando volutamente il fatto che tali oggetti siano contenuti in
una struttura esterna, nonolstante la struttura di controllo (la lista)
esista solo in funzione di quella esterna, l'unica che ospita
i dati di interesse all'applicazione.
Il progettista pigro risolverebbe questo problema semplicemente
imponendo che struct_list sia il primo campo della struttura
ospitante, usando così lo stesso puntatore nei due casi, tramite apposito
cast. La pigrizia è sicuramente una virtù del programmatore,
ma in questo caso si tratterebbe di una scelta limitante, perché
per esempio impedirebbe
di inserire lo stesso dato in più di una lista
(o in una lista e in un'altra struttura dati generica).
Lo strumento utilizzato risiede in due macro
definite in <linux/stddef.h>. Poiché il compilatore
conosce la posizione in memoria dei vari campi di una struttura,
risulta relativamente facile chiedergli la posizione, come spostamento
in byte dall'inizio della struttura, di uno dei campi:
la macro offsetof restituisce proprio tale valore. Basandosi
su questa, la macro container_of risale
alla struttura esterna a partire
dal puntatore ad un membro di cui si conosca il nome simbolico.
In pratica si tratta della generalizzazione dell'approccio «pigro»
già descritto: l'offset dei campi è noto in compilazione, ma non serve
limitarci al caso in cui valga zero.
In figura 2 è rappresentato il funzionamento delle due macro, i cui «prototipi» sono i seguenti:
int offsetof(tipoesterno, nomecampo); tipoesterno *container_of(void *ptr, tipoesterno, nomecampo);
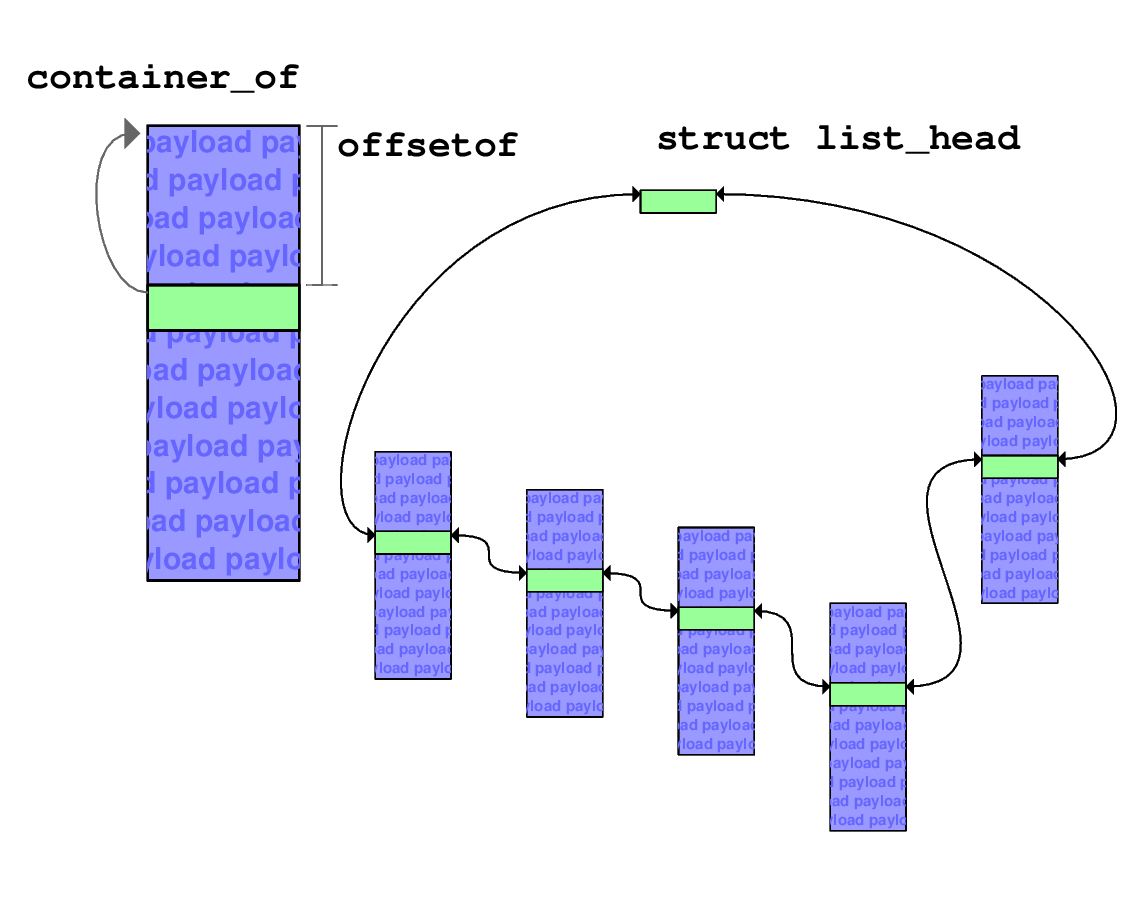
Le due macro, pur essendo sintatticamente due funzioni, non lo sono
semanticamente: gli argomenti indicati in corsivo non sono espressioni
ma nomi simbolici, sostituite tipograficamente del preprocessore in
un costrutto più complesso. È proprio tramite la costruzione tipografica
di una espressione di puntatori che
offsetof restituisce la posizione in byte del campo
nella struttura ospite e container_of produce
l'espressione (completa di cast) che restituisca il puntatore
al tipo esterno a partire dal puntatore al campo interno.
Nonostante le due macro siano un po' arzigogolate, l'unica
operazione che viene eseguita a runtime è la sottrazione di
una costante intera da un puntatore. Rispetto alla lista generica
con il puntatore a void, nella quale il passaggio da una struttura
all'altra richiede un accesso in memoria ed il riferimento ad una diversa
linea di cache, l'uso di queste macro porta a codice molto più efficente.
Il listato 1 mostra il sorgente di klist-int.c, come
esempio di uso delle liste del kernel e
di container_of. Si noti anche l'uso
della macro list_for_each: la pseudo-istruzione
viene espansa in un ciclo for che
scandisce l'intera lista circolare scartando la testa (che non è
contenuta nella struttura ospite, qui struct int_item),
come pure del predicato list_empty.
#include <stdio.h>
#include <stdlib.h>
#include "linux_list.h" /* from 2.6.31 */
struct int_item {
int value;
struct list_head list;
};
int main(int argc, char **argv)
{
struct list_head head;
struct list_head *list;
struct int_item *item;
char line[16];
INIT_LIST_HEAD(&head);
/* read data */
while (fgets(line, 16, stdin)) {
item = malloc(sizeof(*item));
item->value = atoi(line);
list_add(&item->list, &head);
}
/* write it back */
list_for_each(list, &head) {
item = container_of(list,
struct int_item, list);
printf("%12i\n", item->value);
}
/* free it all */
while (!list_empty(&head)) {
list = head.next;
item = container_of(list,
struct int_item, list);
list_del(list);
free(item);
}
return 0;
}
Il riquadro 2 riporta alcune osservazioni sulle prestazioni misurate nelle varie liste.
Riquadro 2 - Prestazioni di list.h
Come si nota dalla figura 1, la differenza nelle prestazioni tra la semplice lista «fai da te» e la lista doppiamente linkata offerta dal kernel è trascurabile (5.02/5.02, 3.17/3.23: al di sotto dell'incertezza di misura). Si tratta di un dato che a prima vista può stupire, in quanto mantenere un doppio collegamento richiede il doppio di istruzioni macchina rispetto a queanto non seva per il collegamento singolo.
Bisogna ricordare però che le istruzioni macchina hanno un tempo
di esecuzione molto variabile, che dipende dalla località spaziale e
temporale del codice, in quanto il tempo di accesso alla memoria
esterna è enormemente maggiore del tempo di calcolo. Perciò, due
puntatori next e prev che risiedono uno di
fianco all'altro e vengono modificati contemporaneamente costano poco
più di un puntatore isolato, mentre l'accesso al payload
tramite puntatore non ha la stessa località.
In ogni caso bisogna ricordare come
le misure di prestazioni effettuate su programmi
sintetici raramente diano informazioni significative sul reale
funzionamento dei sistemi: queste misure hanno variabilità altissime
in base al tipo di processore utilizzato (dimensione della cache,
prestazioni relative del processore rispetto al bus, politiche di
cambio di contesto) e al tipo di applicazione. Per esempio, l'effetto
dell'aggiunta del puntatore prev rispetto al solo
next varia al variare della dimensione
del dato trattato, ma anche in relazione alla dinamicità o meno della
lista di strutture.
Nonostante klist-int e klist-string
riprendano la funzionalità dei quattro programmi di esempio
introdotti inizialmente, conviene ricordare che le liste del kernel
hanno due collegamenti; è perciò possibile inserire e rimuovere elementi in
qualunque punto della lista anche senza avere a disposizione la testa della
lista stessa, oltre a rimuovere gli elementi nello stesso ordine in cui sono
stati inseriti, per esempio inserendo in coda ed estraendo dalla testa.
<linux/list.h> contiene un certo numero di
funzioni aggiuntive per la gestione delle liste. Da list_entry,
un nome alternativo per container_of, passando
per list_for_each_entry (che racchiude
list_entry nel ciclo stesso di scansione della lista) fino a una
serie di funzioni più esotiche per tagliare, ricongiungere, spostare
parti di una lista, o scandire la lista in ordine inverso. Molte di queste
funzioni hanno usi abbastanza specialistici ma nel tempo hanno
trovato il loro spazio nel file di header perché essendo realizzate
in modalità generica possono essere sfruttate da qualunque driver.
La parte finale di list.h definisce una struttura
hlist (half list), la cui testa è formata da un
solo puntatore first, al posto della coppia next
e prev, nosostante le celle della lista contengano comunque
un puntatore all'indietro. Si tratta di una piccola ottimizzazione, in
realtà poco usata in pratica perché viene generalmente preferita
la simmetria della lista doppiamente linkata.
Un'altra struttura dati molto importante offerta dal kernel è quella cosiddetta red-black tree, ovvero albero rosso e nero. Si tratta di un albero binario i cui algoritmi di inserimento e rimozione dei nodi garantiscono di mantenere «abbastanza» bilanciato l'albero. Con «abbastanza» si intende che il ramo più lungo non possa essere più del doppio del ramo più corto.
Riquadro 3 - Gli alberi binari
Un albero binario è un grafo in cui uno dei nodi funge da «radice» e ogni nodo ha zero uno o due figli. Gli alberi binari vengono comunemente utilizzati per la memorizzazione di dati secondo un criterio di ordinamento, data la facilità di scansione ordinata dell'albero stesso. Inoltre ogni albero non-binario può essere facilmente trasformato in uno binario, confermando l'importanza di tale struttura dati anche a livello di studio della complessità computazionale.
Il listato 2 mostra il programma trivialtree, che inserisce in un albero binario le righe di testo ricevute da stdin per poi restituirle ordinate. Il programma fa uso di due puntatori left e right: nel sottoalbero di sinistra vengono memorizzati tutti i dati minori del nodo esaminato e nel sottoalbero di destra tutti quelli maggiori o uguali.
Come nel caso della lista, la semplicità implementativa porta questa struttura ad essere usata molto spesso, anche perché rispetto ad un ordinamento più efficente come può essere qsort, l'uso di un albero al posto di un vettore garantisce che i dati siano ordinati in ogni istante, perché l'ordinamento viene preservato durante gli inserimenti e le rimozioni dei nodi (anche se l'esempio non mostra la rimozione).
Un rb-tree è un albero binario, perciò ogni nodo è dotato al massimo di 2 nodi «figlio»: uno per il sottoalbero «minore» e uno per il sottoalbero «maggiore» del dato ivi contenuto. Ogni nodo dell'albero viene battezzato come rosso o nero, in base alle seguenti regole:
Il rispetto di queste regole garantisce che un ramo non possa allungarsi oltre il doppio di un altro ramo, perché il numero di nodi neri deve essere uguale in ogni ramo ma tra due nodi neri ci può essere al massimo un nodo rosso. Ogni qual volta l'inserimento o la rimozione di un dato portino alla violazione delle regole, occorre ribilanciare l'albero cambiando il colore di alcuni nodi o effettuando una serie di operazioni dette «rotazioni» dell'albero.
Poiché le regole di rotazione sono abbastanza complesse, seppur
indipendenti dall'effettivo contenuto dei nodi, il kernel esporta una
serie di funzioni che possono essere utilizzate anche da chi non abbia
approfondito i meccanismi della struttura dati. L'idea è la stessa
usata per le liste, ma mentre list.h è abbastanza
comprensibile, il codice relativo all'rbtree è molto più
complesso.
Come nel caso di <linux/list.h>, il
file <linux/rbtree.h> definisce una struttura dati
minimale per rappresentare l'albero, lasciando all'utente il compito
di inserirla in una struttura di payload,
usando container_of (o il sinonimo rb_entry
che esplicita l'uso in questo contesto) per recuperare il dato di interesse. A
differenza di quanto accade con le liste, che non richiedono codice dell'utente
perché non richiedono alcun tipo di orginamento, l'utilizzatore di
rbtree.h deve scrivere le proprie
funzioni di scansione dell'albero e inserimento di elementi, poiché
tali operazioni dipendono dallo specifico criterio di ordinamento usato.
Inoltre, a differenza di quanto accade con le liste, realizzate
esclusivamente tramite funzioni inline nel file di header, per
usare gli rbtree occorre chiamare funzioni esterne, che però
intervengono solo per le operazioni di rotazione.
Assumendo che non si vogliano studiare i dettagli implementativi,
la cosa più complicata da fare per l'utente di rbtree.h è
scrivere il codice specifico per il suo utilizzo. Non si tratta in
ogni caso di un'operazine ardua, perché il file di header contiene un
esempio completo di utilizzo dell'albero, facilmente replicabile e
personalizzabile in pochi minuti (o poche decine di minuti).
La scelta di replicare una parte di codice all'interno di ogni funzionalità che usi un rb-tree è dovuta a ragioni di efficienza: a fronte di una replicazione di codice relativamente limitata viene aumentata la località del codice (con effetti benefici sulle prestazioni della memoria cache) diminuendo al contempo il numero di chiamate a funzione e il relativo passaggio di parametri.
Come esempio pratico di utilizzo di una struttura ad albero, i
programmi trivialtree e rbtree, contenuti
negli esempi associati a questo articolo e riportati nei listati 2 e 3,
effettuano un ordinamento di
stringhe lette da stdin. Come per gli esempi delle liste, si
assume che le righe siano al massimo di 16 byte: i programmi
inseriscono tali stringhe nel relativo albero ordinato e le stampano
su stdout una volta raggiunta la fine di stdin.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SLEN 16
struct node {
char s[SLEN];
struct node *left;
struct node *right;
};
int tt_insert(struct node *tree, char *s)
{
struct node *new, **nextp;
if (strcmp(tree->s, s) > 0) {
if (tree->left)
return tt_insert(tree->left, s);
else
nextp = &tree->left;
} else {
if (tree->right)
return tt_insert(tree->right, s);
else
nextp = &tree->right;
}
new = calloc(1, sizeof(*new));
if (!new)
return -1;
strcpy(new->s, s);
*nextp = new;
return 0;
}
void tt_print(struct node *tree)
{
if (tree->left)
tt_print(tree->left);
printf("%s", tree->s);
if (tree->right)
tt_print(tree->right);
}
int main(int argc, char **argv)
{
char line[SLEN];
struct node *root = NULL;
memset(&root, 0, sizeof(root));
/* first line */
if (fgets(line, SLEN, stdin)) {
root = calloc(1, sizeof(*root));
strcpy(root->s, line);
}
/* read other lines and insert them */
while (fgets(line, SLEN, stdin))
if (tt_insert(root, line))
exit(1);
/* print the tree back */
if (root)
tt_print(root);
/* do not free the array */
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "linux_rbtree.h"
#define SLEN 16
/* The structure includes both the payload and the rbtree stuff. */
struct line_rb {
char line[SLEN];
struct rb_node rb;
};
/*
* The following functions are derived from the example in
* The first of them, the search one, is not used as we have unique items.
*/
static void insert_line(struct line_rb *item,
struct rb_root *root)
{
struct rb_node **p = &root->rb_node;
struct rb_node *parent = NULL;
struct line_rb *lrb;
while (*p)
{
parent = *p;
lrb = rb_entry(parent, struct line_rb, rb);
if (strcmp(item->line, lrb->line) < 0)
p = &(*p)->rb_left;
else
p = &(*p)->rb_right;
}
rb_link_node(&item->rb, parent, p);
rb_insert_color(&item->rb, root);
}
static void print_lines(struct rb_root *root)
{
struct line_rb *lrb;
struct rb_node *node;
for (node = rb_first(root); node; node = rb_next(node)) {
lrb = rb_entry(node, struct line_rb, rb);
printf("%s", lrb->line);
}
}
int main(int argc, char **argv)
{
char line[SLEN];
struct rb_root rbroot = {0,};
struct line_rb *item;
/* read data and insert in the rbtree */
while (fgets(line, SLEN, stdin)) {
item = malloc(sizeof(*item));
memcpy(item->line, line, SLEN);
insert_line(item, &rbroot);
}
/* write it back */
print_lines(&rbroot);
/* do not free, like we don't free the array */
return 0;
}
Il programma trivialtree è un semplice albero binario
non bilanciato. La struttura che rappresenta ogni nodo contiene la
stringa (il payload) e i classici puntatori left
e right. A titolo di confronto negli esempi relativi
a questo articolo viene anche fornito il
programma qsort, basato sulla omonima funzione di
libreria. Per verificare la funzionalità dei tre
programmi si possono usare i numeri casuali già usati per le liste,
verificando con md5sum che i risultati dei vari ordinamenti
coincidano tra loro e con il comando sort di sistema:
cat /tmp/nums | time /usr/bin/sort > /tmp/ns1
cat /tmp/nums | time ./trivialtree > /tmp/ns2
cat /tmp/nums | time ./rbtree > /tmp/ns3
cat /tmp/nums | time ./qsort > /tmp/ns4
md5sum /tmp/ns[1234]
In aggiunta a questi 4 programmi di ordinamento, sono stati usati due programmi che allocano i dati per poi restituirli non ordinati. Questo permette di verificare quanto sia il tempo macchina relativo all'operazione di ordinamento e quanto invece il tempo di semplice raccolta e restituzione dei dati.
Come ci si può aspettare, il risultato di qsort è molto
migliore di quello ottenuto dai due algoritmi basati su alberi; oltre ad essere
notoriamente l'algoritmo di ordinamento ottimo, esibisce una notevole
locallità di accessi, che porta ai consueti benefici per gli effetti
di cache. A prima vista possono stupire le scarse prestazioni
di sort, che si spiegano però ricordando come il criterio di
ordinamento dipenda dai criteri di internazionalizzazione (caratteri
accentati eccetera), dalla divisione in campi
delle righe di input e da altri fattori molto più complessi di uno
strcmp. Inoltre, non
sappiamo l'algoritmo usato (io non lo so nemmeno dopo aver aperto i
sorgenti, ma credo che con un po' di pazienza si possa capire).
Un'altra osservazione sorprendente è notare come i tempi di calcolo associati all'rbtree del kernel siano migliori di quelli dell'albero binario banale, quello che tutti abbiamo scritto al corso di fondamenti di informatica e mille altre volte nella nostra vita. Possibile che tutta la complessità di rbtree non abbia un'influenza negativa sulle prestazioni?
Come nel caso di list.h, in realtà, l'implementazione generica
è fortemente ottimizzata proprio in virtù della sua genericità:
ogni miglioramento ottenuto è immediatamente sfruttato da tutto il
codice che si appoggia su questa implementazione, quando invece
l'albero scritto mille volte, ma ogni volta per essere
usato una volta sola, non riceve altrettante attenzioni.
Per esempio, in struct rb_node il colore di un nodo
(rosso o nero: quindi 1 bit) non viene memorizzato in un campo a se
stante ma nel bit meno significativo del puntatore al padre. Questa
scelta si basa sulla nozione che tutti i puntatori sono multipli di 4
su ogni macchina che possa ospitare questo codice, unita alla
constatazione che gli accessi in memoria sono più costosi
dell'estrazione aritmentica di campi di bit da un valore che stiamo
comunque già ospitando in un registro macchina.
Un programma che sfrutti rbtree nel proprio codice deve
aiutare rbtree.h definendo alcune procedure. Il listato
3 presenta inserimento e scansione, ma spesso occorre anche una
procedura di ricerca. Vediamo di descrivere le tre procedure.
La ricerca (non presente nell'esempio) è una scansione dell'albero
per cercare una corrispondenza tra un nuovo dato e quelli già
presenti nell'albero. Il codice assomiglia molto a insert_line
del listato 3, con la differenza che una ricerca restituisce il puntatore al nodo
corrispondente o NULL in caso di insuccesso, senza
effettuare inserimento. Non si tratta di una procedura che possa
essere fornita da rbtree.h, in quanto il criterio di
ordinamento non è generico. L'idea di fornire un puntatore alla
funzione di confronto (in questo caso strcmp), come viene
fatto per la qsort di libreria, sarebbe
perdente come prestazioni visto che quasi tutti gli usi ordinano semplicemente
con un criterio intero (un indice o un indirizzo).
Anche l'inserimento di un nodo nell'albero (esempio: insert_line nel listato 3) deve essere fornito dall'utente perché richiede gli stesso confronti della ricerca, con la differenza che il nodo va collegato all'albero e l'albero deve essere ribilanciato. Per questo vengono chiamate le due funzioni rb_link_node, che aggancia i puntatori talvolta violando le regole che garantiscono il bilanciamento), e rb_insert_color che si preoccupa di ribilanciare l'albero se necessario.
La terza funzione dell'utente è la scansione, per accedere a tutti i nodi secondo l'ordinamento scelto. In questo caso basta partire da rb_first(root) passando ogni volta d rb_next(node), come nella funzione print_lines del listato 3.
È utile notare come tutte e tre le funzioni vengono realizzate in maniera iterativa, piuttosto che ricorsiva come in trivialtree (listato 2). L'algoritmo iterativo è leggermente meno intuitivo e perciò più difficile da scrivere, ma richiede meno risorse, sia come calcolo sia come dimensione dello stack, particolare molto importante quando si lavora in spazio kenrel. Tutti gli esempi d'uso di rbtree mostrano procedure iterative ed è bene seguire tali esempi; d'altra parte trivialtree è l'esempio di cosa si scrive in cinque minuti: la realizzazione di una sua versione iterativa e il confronto delle prestazioni e dell'uso di stack è lasciato come esercizio per il lettore.
Come sappiamo, il problema del semplice albero binario sta proprio nel non essere automaticamente bilanciato: se i dati in ingresso non sono equamente distribuiti nello dominio dei valori le sue prestazioni hanno un crollo catastrofico. Se, nel caso pessimo, i dati in arrivo sono già ordinati, il tempo necessario alla costruzione dell'albero cresce col quadrato del numero di elementi. La figura 4 riporta qualche misura effettuata con gli stessi programmi di figura 3, ma usando centomila numeri invece di dieci milioni.
sort e qsort migliorano le prestazioni quando i dati di ingresso sono già ordinati perché devono effettuare meno scambi di dati. Il programma rbtree non mostra differenze apprezzabili, nonostante il continuo lavoro di ribilanciamento dell'albero, mentre il semplice albero binario rivela subito la sua inefficenza; inoltre raddoppiando il numero dei dati il tempo di calcolo quadruplica, confermando la teoria: per ri-ordinare dieci milioni di numeri già ordinati servirebbero 100 ore sulla stessa macchina che ci mette 22 secondi se i numeri sono disposti casualmente.
Sempre a proposito di prestazioni, occorre ricordare ancora una volta come gli alberi mantengano l'ordinamento dei dati in ogni momento e sono perciò strumenti insostituibili in situazioni dinamiche, nelle quali i dati entrano ed escono dal sistema in continuazione e qsort non è nemmeno da prendere in considerazione.
In pratica, è molto più raro dover ordinare nella sua totalità un gruppo di valori di quanto non sia tenere sempre ordinato un insieme di dimensioni variabili. In particolare nella programmazione di sistema, occorre spesso ricercare un elemento all'interno di un insieme: per esempio una pagina di memoria a partire dal suo indirizzo o un file in una directory di filesystem. Nonostante alcuni problemi siano risolvibili brillantemente tramite hash table, scavalcando completamente la necessità di ordinare i dati, le situazioni che necessitano di ordinamento sono numerosissime: non dovrebbe stupire, anche a fronte della bontà dell'algoritmo e dell'implementazione di Andrea Arcangeli, che nella versione 2.6.33 del kernel si contino 90 sorgenti C che chiamano rb_insert_node nei contesti più vari: dai filesystem alla memoria virtuale e alle misure di prestazioni.
Nonostante le strutture dati siano spesso viste come oggetti di fredda teoria e copioso sudore, ritengo abbiano ancora un certo fascino quando affrontate con intelligenza cercando di fattorizzare gli sforzi (e il sudore) in implementazioni facilmente riutilizzabili. Nel kernel Linux, in particolare, gli anni di esperienza negli ambiti più disparati uniti al costante tentativo di eccellere hanno portato ad ottimi esempi di programmazione facilmente riutilizzabili anche in spazio utente -- ricordando però di non violare i termini di licenza.
Ci sono altri ottimi esempi di strutture generiche nel kernel, ma credo che le semplici liste e i difficili rbtree diano già idea di cosa si può fare tramite trucchi di preprocessore e funzioni di libreria. Inoltre, se vogliamo usare queste strutture in un sistema piu` piccole rispetto a Linux (come un microcontrollore), liste e alberi sono piu` che sufficienti, al limite potrebbe servire un semplice meccanismo di hash, ma lasciamo al lettore l'onere di realizzarlo, o trovarlo.
Tutte le varie forme di alberi sono descritte con dovizia di particolari e pseudo-codice nella pagine di Wikipedia, che include anche una categoria "strutture dati" abbastanza completa.
Riguardo al codice specifico discusso qui, i seguenti file nei sorgenti del kernel sono un'utile lettura:
Documentation/rbtree.txtinclude/linux/list.hinclude/linux/rbtree.hlib/rbtree.crb_):
fs/ext3/dirc.cmm/mmap.cOltre, naturalmente, agli esempi di questo articolo, che si trovano in datastruct-src.tar.gz),